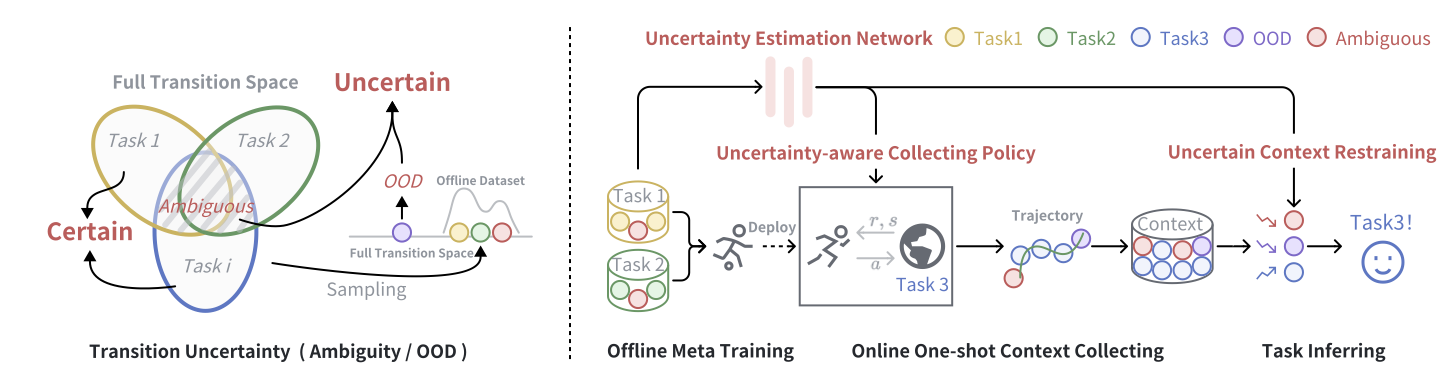
 | CERTAIN: Context Uncertainty-aware One-Shot Adaptation for Context-based Offline Meta Reinforcement LearningInternational Conference on Machine Learning (ICML) 2025 We propose CERTAIN to tackle context ambiguity and OOD issues in one-shot adaptation for COMRL by leveraging uncertainty-aware task representation learning and context collection. Build upon heteroscedastic-like uncertainty estimation, our method can identify unreliable contexts and then lead to more robust policies. Paper Code |

Publications
You can also find my articles on my Google Scholar profile.
2025
2024
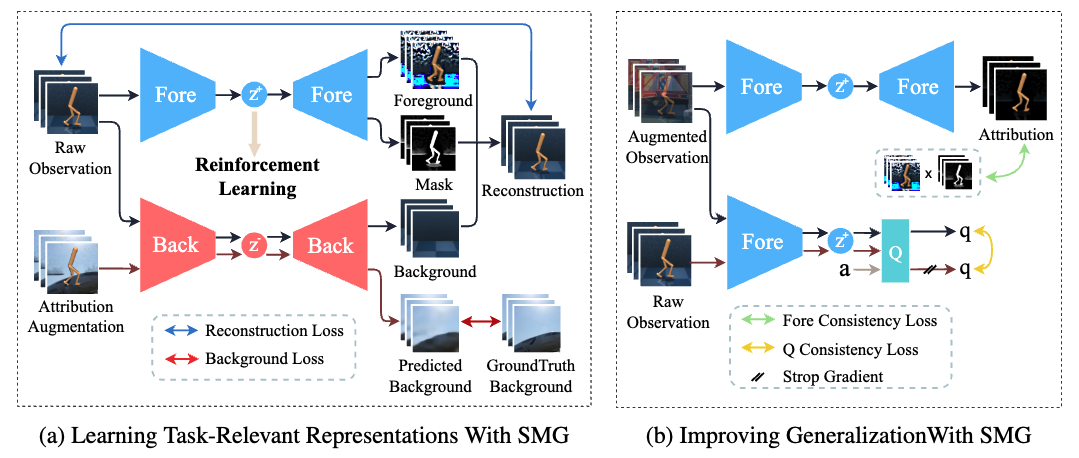 | Focus on what matters: Separated models for visual-based rl generalizationAnnual Conference on Neural Information Processing Systems (NeurIPS) 2024 We propose SMG, which utilizes a reconstruction-based auxiliary task to extract task-relevant representations from visual observations and further strengths the generalization ability of RL agents with the help of two consistency losses. Paper Code |
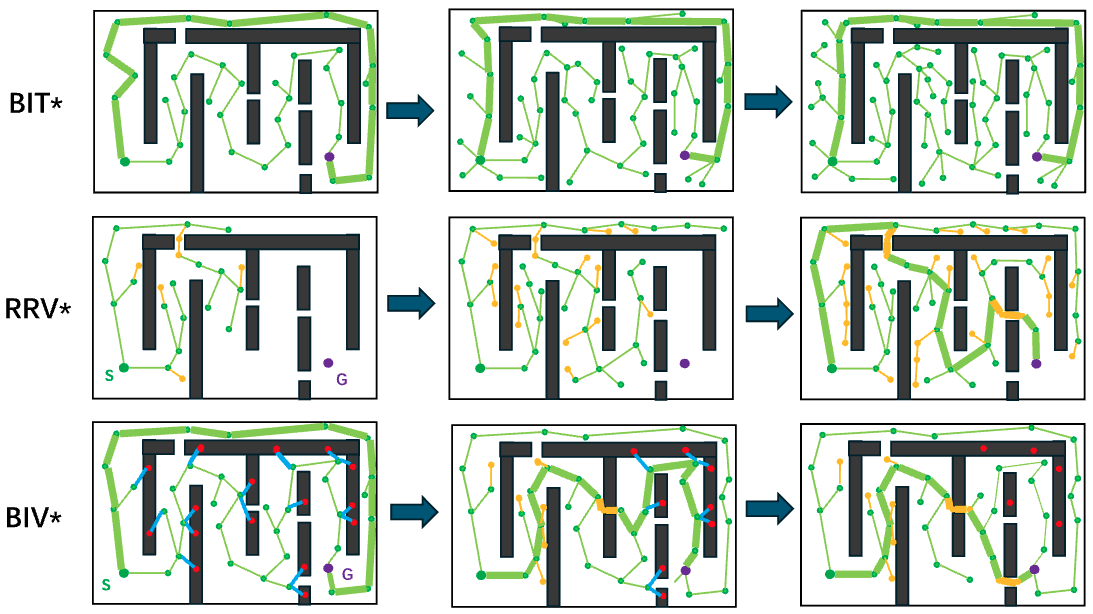 | Batch Informed Vines (BIV*): Heuristically Guided Exploration of Narrow Passages by Batch Vine ExpansionIEEE Robotics and Automation Letters (RA-L) 2024 We propose an enhanced heuristic-based vine expansion method, termed Batch Informed Vines (BIV). BIV utilizes path information from the current search tree as heuristics to prioritize the exploration of narrow passages leading to lower solution cost. Additionally, we propose a batch vine expansion strategy, which includes exploration of “Closer to Unexplored Obstacle” (CTUO) nodes and batch expansion. Paper |
2023
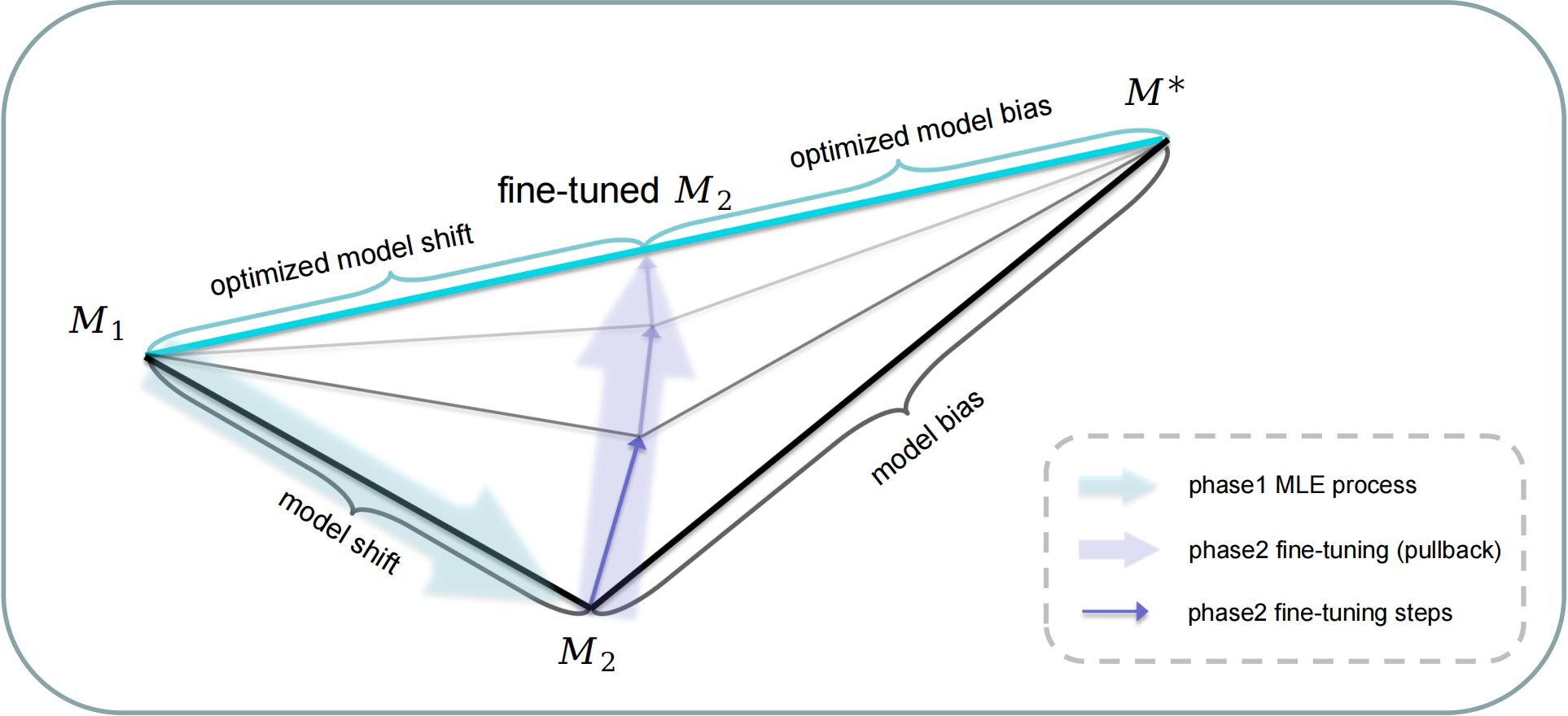 | How to fine-tune the model: unified model shift and model bias policy optimizationAnnual Conference on Neural Information Processing Systems (NeurIPS) 2023 We theoretically derive an optimization objective that can unify model shift and model bias and then formulate a fine-tuning process, adaptively adjusting model updates to get a performance improvement guarantee while avoiding model overfitting. Paper Code |
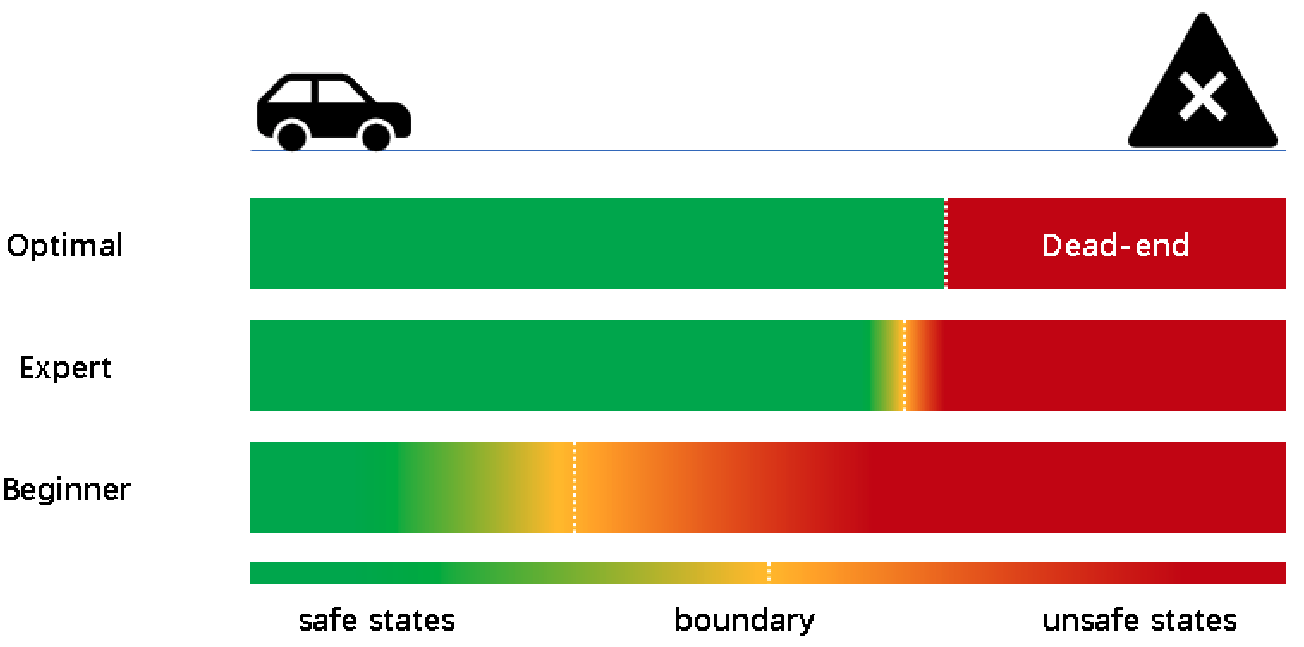 | Safe reinforcement learning with dead-ends avoidance and recoveryIEEE Robotics and Automation Letters (RA-L) 2023 We propose a method to construct a boundary that discriminates between safe and unsafe states. The boundary we construct is equivalent to distinguishing dead-end states, indicating the maximum extent to which safe exploration is guaranteed, and thus has a minimum limitation on exploration. Paper Code |
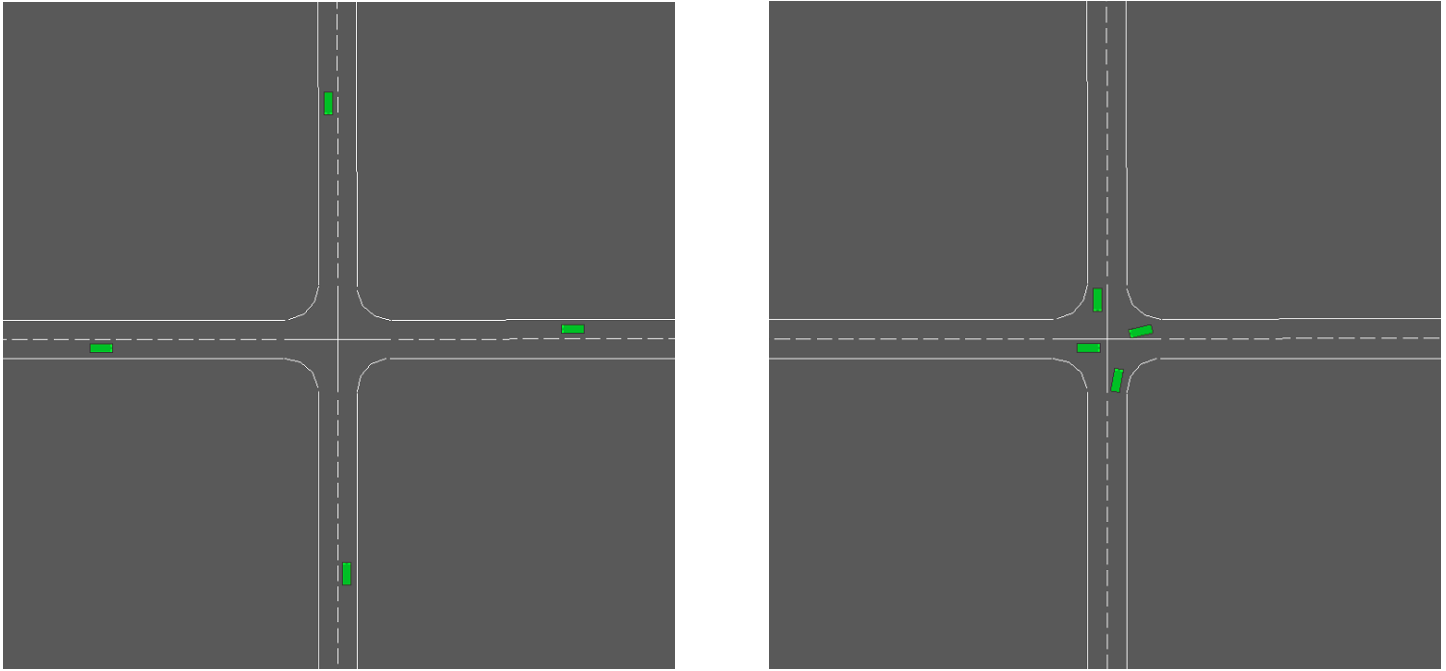 | Multi-agent decision-making at unsignalized intersections with reinforcement learning from demonstrationsIEEE Intelligent Vehicles Symposium (IV) 2023 We propose QMIXwD to pre-train the policy using demonstration data consisting of expert data and interaction data to improve the initial performance of agents and improve exploration, as well as to reduce the distributional shift between the demonstration data and the environmental interaction data. Paper Code |
2022
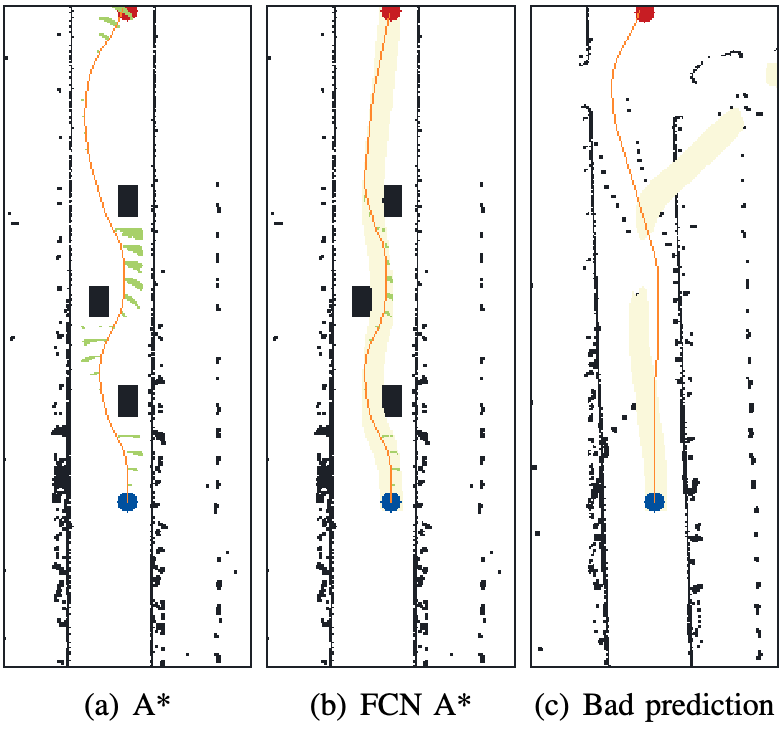 | Real-time Multiple Path Prediction and Planning for Autonomous Driving aided by FCN6th CAA International Conference on Vehicular Control and Intelligence (CVCI) 2022 We propose FCN-A, a real-time multiple path planning method combining semantic segmentation with the traditional graph-based search. A fully convolutional neural network (FCN) was first designed to learn the optimal path area generated by an A based path planning method in various real and simulated environments. By injecting noises into localization information, the generalization ability of the neural network is greatly enhanced facing inaccurate localization results. Then, multiple possible path areas inferred by the FCN are adopted as constraints for the following A* based path planning. Paper |
2019
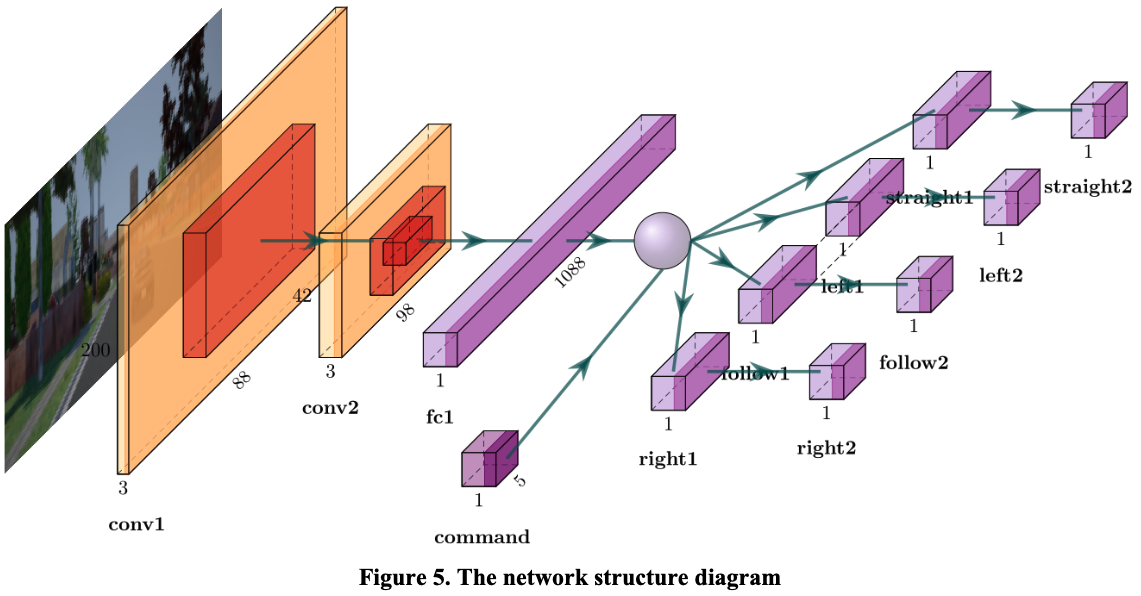 | Learning how to avoiding obstacles for end-to-end driving with conditional imitation learningInternational Conference on Signal Processing and Machine Learning (SPML 2019) We use CARLA, an autonomous driving simulator, to collect 6 hours of human driver reactions to obstacles under given commands (follow, go straight, turn left, turn right). We propose a Behavior-Cloning network with a modified loss function that emphasizes steering errors for higher accuracy. Results show that image augmentation is crucial for training, and a speed limit helps prevent unexpected stops. Paper |
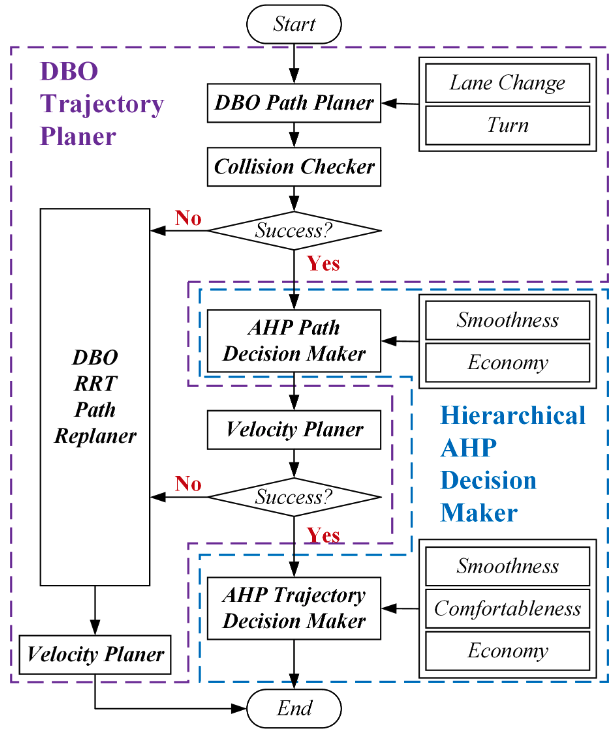 | DBO Trajectory Planning and HAHP Decision-Making for Autonomous Vehicle Driving on Urban EnvironmentIEEE Access 2019 We propose a Driving Behaviour-Oriented (DBO) trajectory planner and Hierarchical AHP (HAHP) decision-maker for intelligent vehicles. Unlike purely minimizing distance/time, our approach ensures actuator constraints, comfort, and strict traffic rule compliance for structured road driving. Paper |